
%20(1).png)
Maia changes the equation of data work
Enjoy the freedom to do more with Maia on your side.



Every CDAO who has run a migration program has a version of this story.
Year one: the scope looks manageable. Year two: the scope has tripled. Year three: the program is on pause "until after the next release cycle." The consulting firm is still engaged. The legacy pipelines are still running.
The standard explanation is that migration is hard. Legacy transformation logic is complex. The business continuity risk is real. The team has too many competing priorities. These things are true. But they are symptoms.
The structural cause is simpler. Migration has been architected as a capital project: defined scope, fixed budget, a go-live date, consulting dependency. That architecture produces a predictable failure taxonomy regardless of how good the team or the data estate is.
This piece is about that taxonomy, and what changes when you replace the architecture itself.
If you have run a migration program, you know these four stages. They do not always arrive in the same order, but they always arrive.
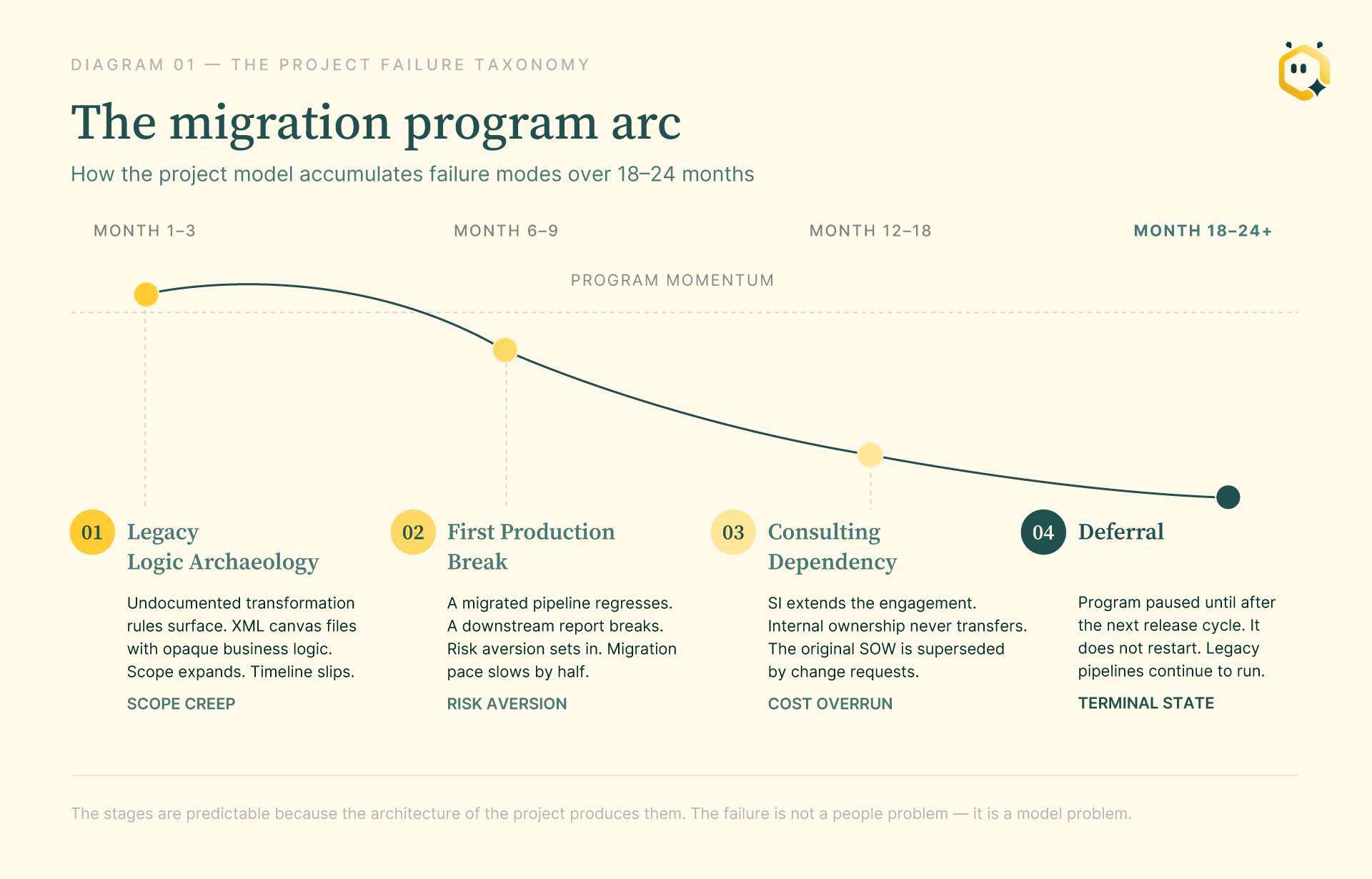
Stage 1: Legacy logic archaeology. The team begins migration and immediately discovers that the pipelines contain undocumented business logic that nobody wrote down. Transformation rules sit buried in XML canvas files where every icon position change generates a git diff. Datasets are extracted into proprietary binary formats with no schema documentation. Senior engineers spend weeks reverse-engineering what a pipeline does before they can migrate it. Scope expands. Timeline slips. The consulting estimate, already generous, turns out to have been optimistic.
Stage 2: The first production break. One migrated pipeline regresses in production. A downstream report breaks. A finance director calls. The risk aversion that was already present in the room doubles overnight. The migration pace slows by half. What was already a 12-month program starts looking like 24.
Stage 3: The consulting dependency. The system integrator extends the engagement because it has to. The internal team never fully owned the migration scope, and the archaeology problem is still producing surprises. The original statement of work is superseded by change requests. Internal ownership does not transfer. The organization has paid for the migration twice and still does not have full control of the pipeline estate.
Stage 4: Deferral. The program is paused after the next release cycle. There is a roadmap commitment that cannot slip. The migration goes on the backlog, and it does not restart.
Every CDAO who has lived through this recognizes it. The stages are predictable because the architecture of the project produces them. It is a model problem, not a people problem.
The project model has a fatal flaw: it concentrates all the risk, technical, commercial and organizational, into a single bounded event. The go-live date becomes a binary outcome, and every regression, archaeology surprise and day-rate overrun becomes a reason to pause.
The runtime model inverts this. Instead of a program with a start date, a go-live date and a consulting dependency, migration becomes a background process. Autonomous agents continuously parse, translate and validate pipeline logic against your target architecture. Engineers do not manage a migration program. They review a queue.
That changes the risk profile of every decision. In the project model, a production regression is a program-level event: it triggers risk aversion and slows the whole migration. In the runtime model, a regression in one cohort is isolated, flagged in the queue, and fixed while the rest of the migration continues. There is no big-bang go-live to protect.
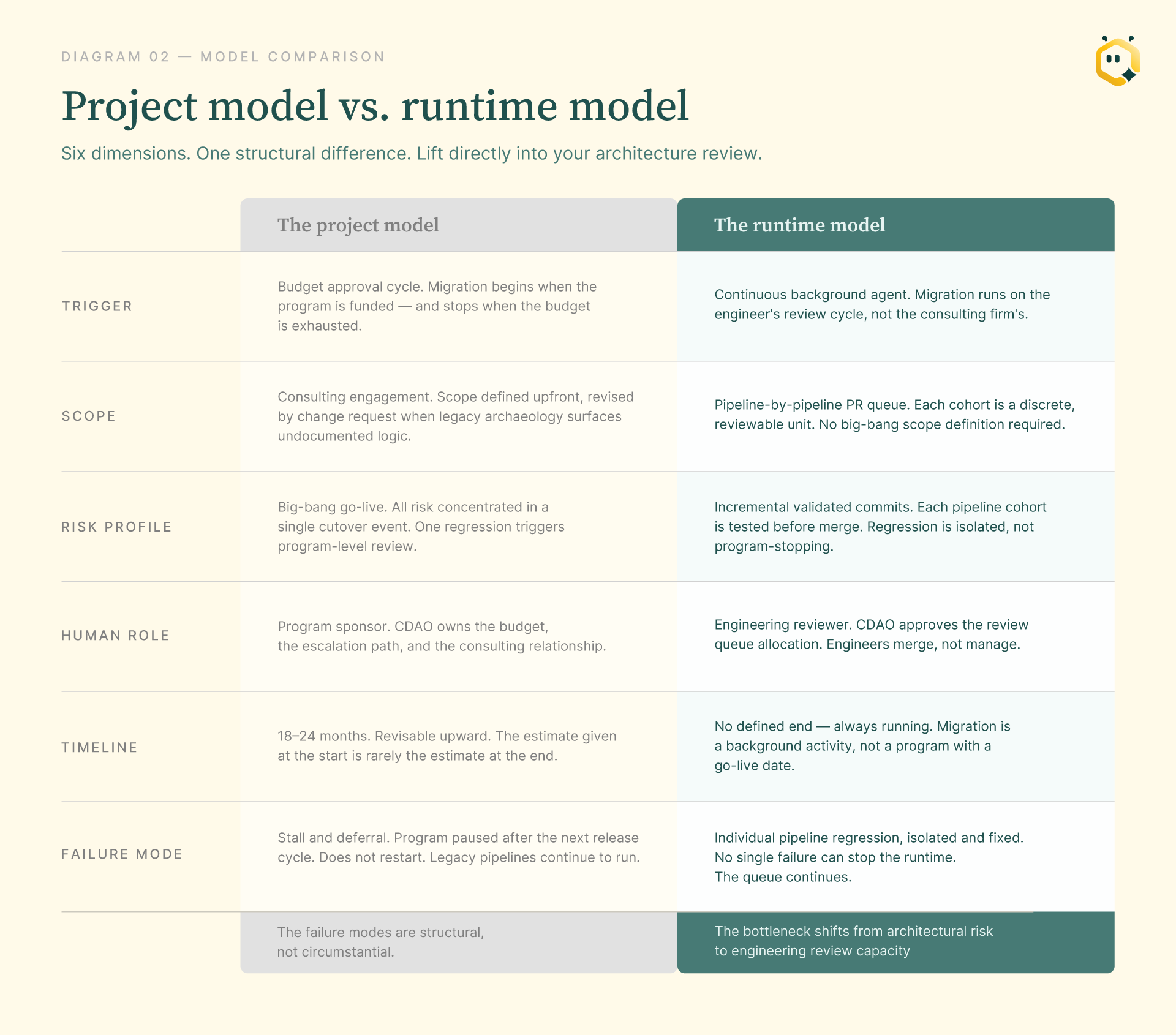
That table is the CFO and CTO artifact. The CDAO's job in the runtime model is to approve a review cycle, not to sponsor a program. The bottleneck shifts to engineering review capacity: a resourcing problem, not a structural one.
Continuous migration needs an operating architecture, not just a tool. Eight stages run as a flywheel, not a sequence: the agent learns from each review decision and feeds it back to intent. Migration does not complete; it runs.
.png)
"Maia offers a glimpse into the future of data engineering. It's intuitive, powerful, and feels like a real accelerant for how teams build with data."
Sridhar Ramaswamy, CEO of Snowflake
Moving from the project model to the runtime model does not require a program relaunch. It requires three moves.

Move 1: Migrate one self-contained dependency cluster. Identify a regulated, high-touch pipeline cohort with no unresolved downstream dependencies. Run it through the agent. The engineer reviews and merges. Starting with a cohort rather than a single pipeline keeps the before/after state clean and the result production-ready. This takes days, not months.
At Balfour Beatty, a FTSE-listed infrastructure company running 1,300 Informatica PowerCenter pipelines that support 800 active reports, Maia's Migration Agent parsed legacy XML logic that had taken a senior engineer a full week to reverse-engineer. It completed the analysis in six minutes. The multi-year program that had stalled entirely now has a six-month delivery window for the first time.
Mark Hume, Head of Data at Balfour Beatty: "We'd almost given up hope. We'd started just rewriting SQL to pull in the data and model it ourselves. This has given us a new hope that we can shortcut that process."
Move 2: Measure for one quarter. Track throughput delta and engineering hours reclaimed against conservative benchmarks. EDF Energy, running Maia across federated data teams, recorded a 75% productivity gain. A global Fortune 100 pharmaceutical manufacturer reduced pipeline build time from eight hours to 30 minutes for analyst workstreams, a 93% reduction. Sophos, migrating from Informatica PowerCenter, achieved a 98% productivity lift across the engagement.
The capacity problem behind these numbers is not going away. The Ascend.io 2025 Pulse Survey found that 95% of data engineers report being at or over their work limit, and that only 5% have implemented automation tools despite 85% planning to within 12 months. The runtime model does not solve that by hiring. It solves it by changing what the migration activity requires.
Move 3: Industrialize. Expand to further pipeline cohorts and let the agent run continuously. Migration becomes a background activity. The engineering team stops managing a migration and starts reviewing a queue while shipping roadmap work in parallel. EDF Energy completed its migration to Maia and Snowflake in under a year, and freed 75% of federated data team capacity for net-new data product work that was structurally impossible to reach at manual speed.
This is the part that does not show up in the project plan. The senior engineers who spent weeks reverse-engineering legacy logic get that time back, and they spend it building data products instead of excavating old ones. The migration stops being the thing the team is trapped inside.
The question is whether your migration model produces the failure taxonomy every time, or whether you replace the model.
The project model has a predictable ceiling. Past a certain level of legacy complexity, the undocumented XML canvas files, the binary extracts with no schema, the pipelines maintained by contractors who left three years ago, the human archaeology becomes the rate-limiting factor. No headcount fixes it. No SI extension fixes it.
When agents run continuously, archaeology becomes a throughput problem. The rate limiter is engineering review capacity, which you can resource, not pipeline complexity, which you cannot wish away.
The 64% of teams currently spending more than half their time on repetitive and manual data tasks are not inefficient. They are running the project model in a world that has outgrown it. The Wakefield/Fivetran research puts the cost in plain terms: roughly $520,000 a year in senior engineering capacity consumed by pipeline maintenance alone. An agent that runs continuously does not need a go-live date. It needs a review queue.
If you are taking this to your CTO or CFO, the argument is not that migration is easy. It is that the failure has been structural, and the structure can be changed.
The runtime model requires agents that parse legacy logic at machine speed, propose validated replacements, and integrate into the engineering review cycle without new program overhead. That is the capability question for any evaluation. Not "can you migrate our pipelines?" because every vendor will say yes, but "can your agents run continuously, without a consulting dependency, against a cohort review queue?"
The CDAO's role in that model shifts from program sponsor to engineering capacity allocator. That is a different conversation, and a shorter one.
Maia is the AI data engineering platform built on 15 years of pipeline engineering experience. The Migration Agent translates legacy workflows, including XML-based workflow files and proprietary format extracts, into validated, production-ready pipelines on the engineer's review cycle. No go-live date required.

