

Maia changes the equation of data work
Enjoy the freedom to do more with Maia on your side.


AI coding assistants and co-pilots made individual data engineers faster. Team delivery didn't move. A theory from 1967 explains why, and points to the fix.
Sam shipped three pipelines this week. An AI coding assistant scaffolded the transforms, drafted the tests, and turned what used to be a half-day of work into about an hour. Sam's personal stats look great. Lines of code, pull requests opened, time to first commit.
The backlog is exactly as long as it was on Monday.
If that contradiction sounds familiar, a piece of computer science from 1967 explains it.
Gene Amdahl's law says the maximum speedup of any system is capped by the part you didn't speed up. Make one stage infinitely fast, and the whole thing still can't move faster than whatever you left untouched.

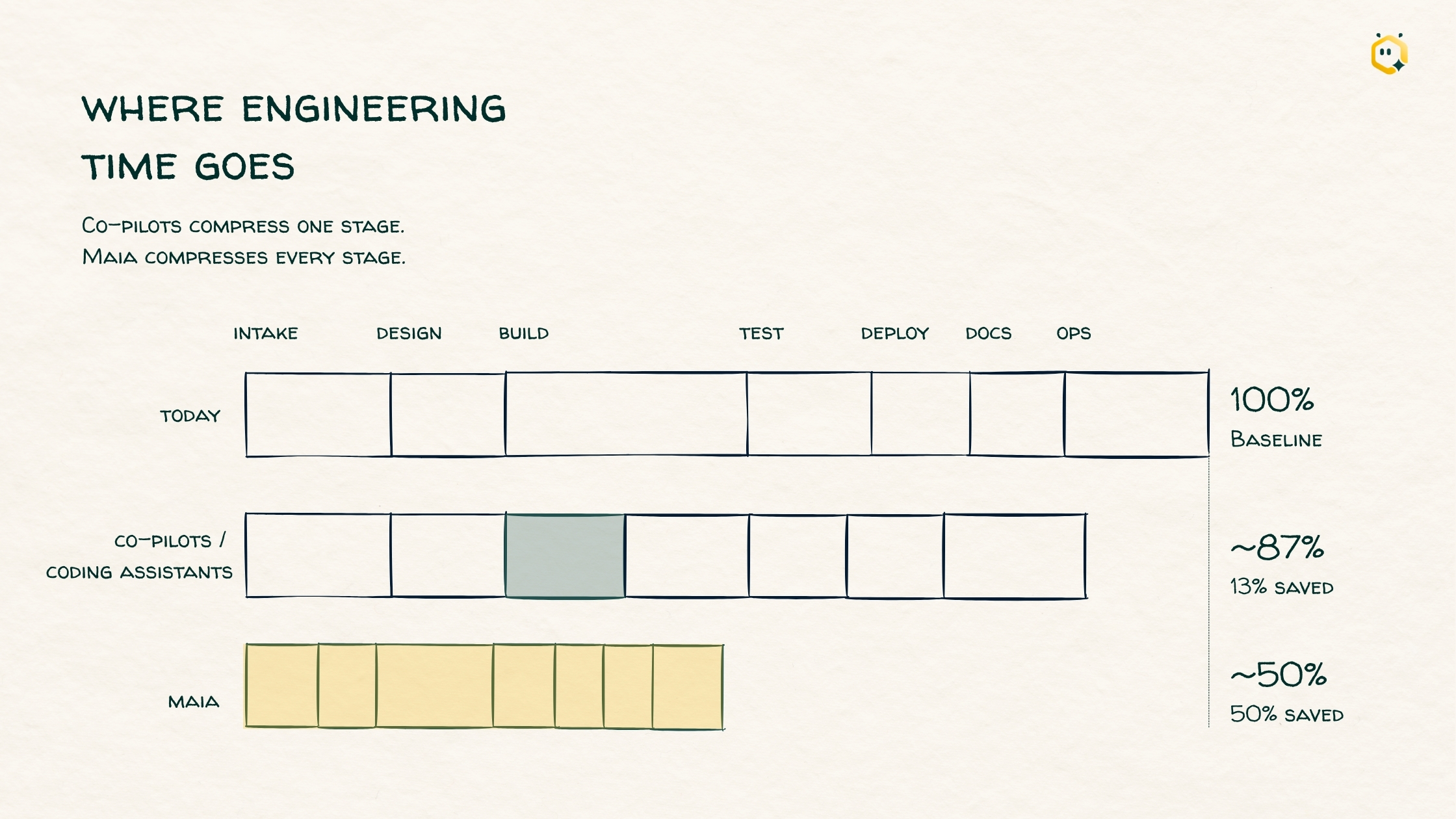
Writing pipeline logic, the heads-down work an AI coding assistant accelerates, is one slice of the data engineering lifecycle. Call it 20%. The rest is review, data contracts, quality validation, governance sign-off, the platform team's promotion window, and the downstream analysts and ML engineers who have to trust the output before it counts as shipped.
Read the third row. An assistant that writes pipelines instantly still only moves team delivery by about a quarter. The other 80% sets the ceiling.

9:10. Sam picks up a pipeline. With an AI coding assistant, the transformation and a first set of tests are drafted in 25 minutes. Before, this was most of a morning.
11:15. A second pipeline is open for review. A third is in flight.
2:00. Raj, the reviewer, finally reaches the queue. The agent built context so fast that he now has to rebuild slowly, tracing lineage, checking the SCD logic, and working out which downstream dbt models are affected.
3:30. A pipeline from yesterday is still waiting on a data contract change. The analytics engineer who owns the consuming model has been in meetings since 9.
4:45. Another is queued for the Thursday promotion window. It's Tuesday.
By Friday, Sam has built more pipelines than ever and shipped fewer than expected. Raj is behind and starts skimming. A schema change slips through and breaks a finance dashboard. The board shows the same throughput as last quarter.
Sam's pace is real. The system around Sam still runs at human speed, and a faster agent just pointed a firehose at it.
If 80% of the lifecycle is planning, collaboration and validation, that's where the speed is. Amdahl's Law tells you the next real unit of throughput comes from the part you've been treating as fixed background cost.
Redesign how the review, validation, and promotion stages work. Smaller batches, clearer ownership, and standards encoded into automation instead of living in senior engineers' heads. Then put AI to work where the queue forms: review, validation, promotion.
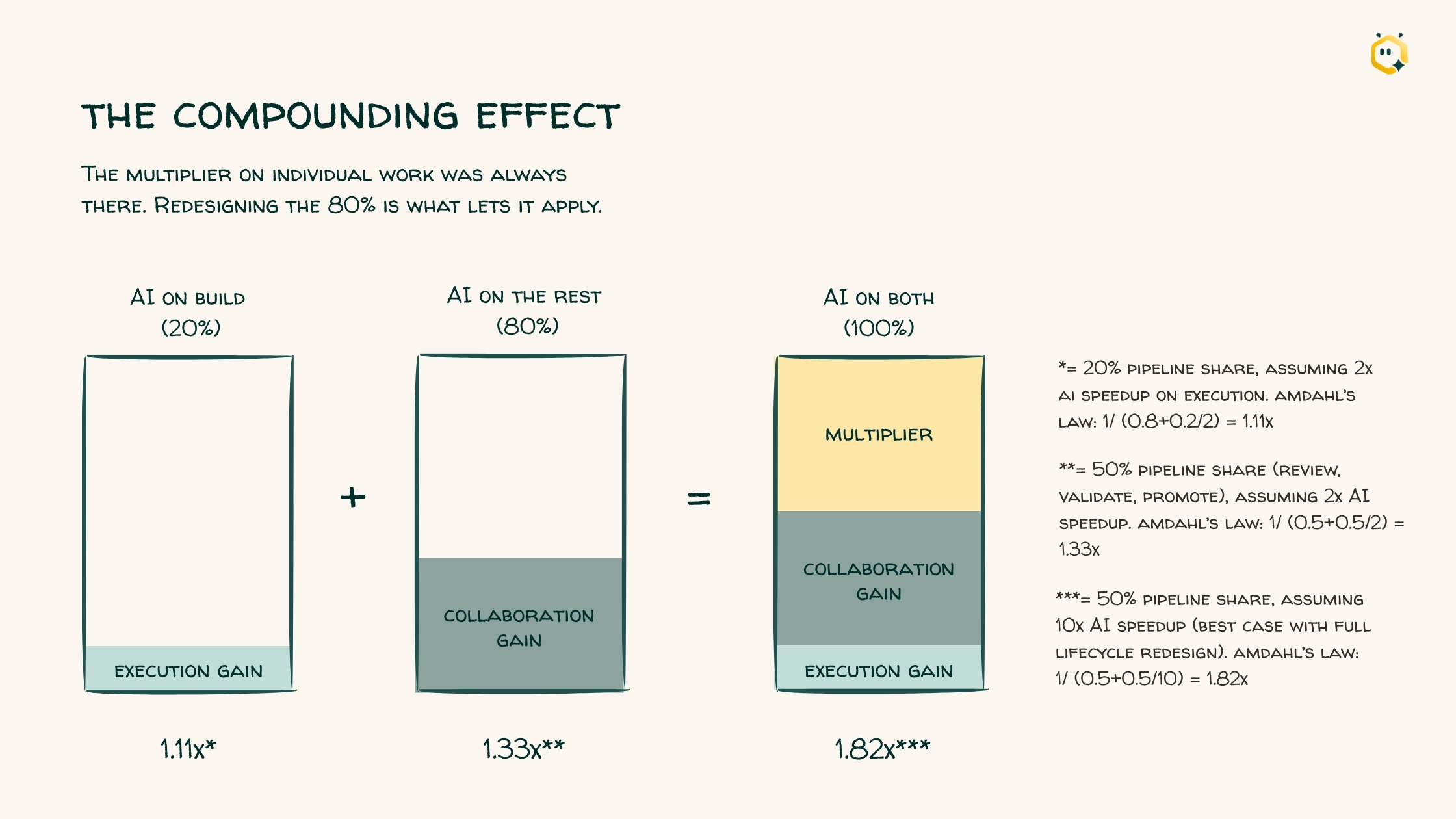
Do both, and something compounds. You get the collaboration improvement, and you finally get the full multiplier on the individual work that was capped all along.
Amdahl's Law tells you the next real unit of throughput comes from the part you've been treating as fixed background cost.
Agentic data engineering means treating the whole delivery lifecycle as the unit of automation, not just the code-writing stage. This is the design principle behind Maia, Matillion's AI Data Automation platform, and the reason it's built as a team of agents rather than a single coding assistant.
Maia Team is an agentic system mapped to the actual roles in the delivery lifecycle: Pipeline Builder, Data Quality Engineer, Migration Specialist, DataOps Agent, FinOps Agent, and Connectivity Agent. The Data Quality Engineer works on the validation stage. The DataOps Agent works on orchestration and promotion. In Amdahl's terms, Maia raises the share of the lifecycle being accelerated, instead of just speeding up the same 20% harder.
Two newer parts of the platform go at the bottleneck directly.
The Maia Context Engine continuously models what a reviewer normally reconstructs by hand: schema, naming conventions, CI/CD rules, drift history, and the tribal knowledge that usually lives in one senior engineer's head. Remember Raj, slowly rebuilding the context that the agent built fast? The Context Engine closes that gap. Context stops being re-derived for every review. It becomes shared, current, and queryable.
Maia Mission Control is the supervision layer across every agent and pipeline. One data lead sees what every agent is doing, where pipelines are blocked, and which changes are safe to move — overseeing roughly 10× the throughput of a single engineer writing code. It's the review gate, redesigned for a team that now includes agents.
Maia's agents run on the pipeline engine that already moves production data for Cisco, DocuSign, and Autodesk. They understand pipeline semantics: SCD types, medallion layers, CDC, lineage. Output is versioned, tested, and documented. The claim is falsifiable — either it ships through your existing CI/CD, or it doesn't.
The first wave of AI in data engineering got measured the easy way: how fast can one engineer write a pipeline? It's the wrong question. It optimizes the slice Amdahl's Law already told us was capped.
The honest question is the one a CDAO answers to a board:
How fast can the team get trusted data into production without burning people out, and is the backlog finally shrinking?
Measuring that needs a different instrument. A delivery metric for data engineering, the way DORA gave software teams one. That's a conversation worth having, and one Matillion intends to lead.
In the meantime, the number that actually moves a backlog: Maia has automated more than 22,000 hours of manual data engineering across its user base. Roughly 11 full-time years of effort were handed back to the teams that were drowning in it.
A faster keyboard was never going to do that. A faster team will.
Book a demo and see how the Maia Team works.

