.png)

Maia changes the equation of data work
Enjoy the freedom to do more with Maia on your side.


The architecture behind every modern cloud data platform, and why it changes what's possible with your data
MPP splits large data jobs across independent compute nodes that work simultaneously, no bottlenecks, no single point of failure. It's the reason modern cloud data warehouses like Snowflake, BigQuery, and Redshift can handle petabyte-scale queries in seconds. Unlike traditional single-server SMP systems, MPP scales horizontally as your data grows. Maia, the AI Data Automation platform, featurespushdown ELT architecture, which is built specifically to exploit this, keeping computation inside your cloud platform and out of your pipeline tooling.
The way data gets processed at scale isn't just a technical detail, it's the difference between analytics that move at the speed of the business and analytics that don't.
Massively Parallel Processing (MPP) is the architectural backbone that modern cloud data platforms are built on. As data volumes compound and the expectations on data teams grow, it's worth understanding exactly why MPP matters, and what it makes possible when you pair it with the right tooling.
This article breaks down what MPP is, how it compares to older approaches, and why it's foundational to ELT and AI-ready data infrastructure.
Key takeaways:
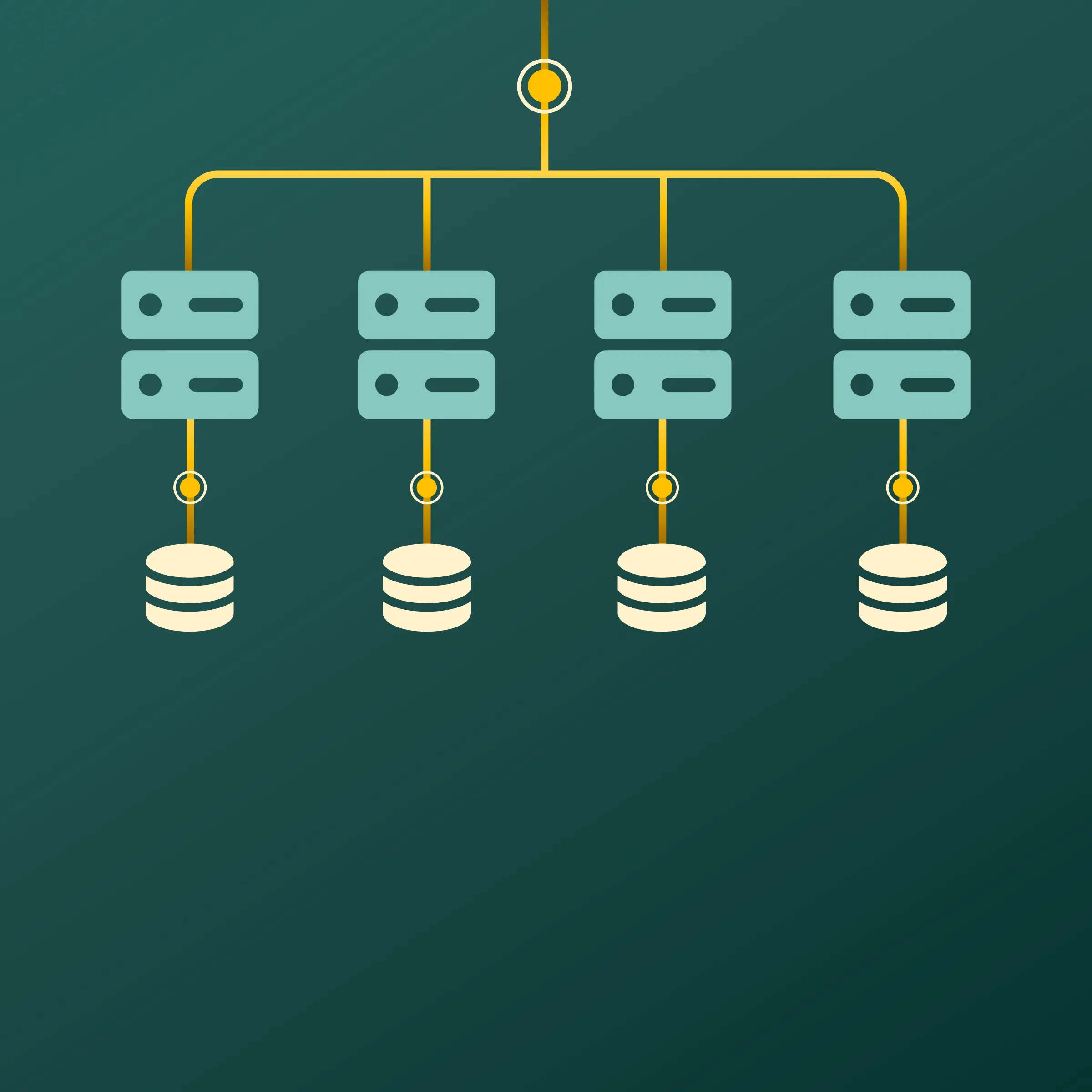
Massively Parallel Processing (MPP) is a computing approach where large data jobs are broken into smaller tasks and executed simultaneously across multiple independent compute nodes. Each node processes its own slice of data, and the results are combined once all nodes finish. The net effect: what would take a single system hours can be done in minutes.
Think of it like a relay race redesigned as a sprint. Instead of one runner completing the whole course, you split the track into segments and run them all at once. The finish line arrives faster because the work is genuinely happening in parallel, not just faster on a single thread.
In a typical MPP setup, each node has its own CPU, memory, and storage. These nodes work independently but stay in sync during query execution. When a query is triggered, it gets broken down into smaller tasks, which are distributed across nodes to be processed in parallel. Once each node finishes its bit, the results are combined and returned.
In a typical MPP setup, each node has its own CPU, memory, and storage. When a query runs, it's broken into sub-tasks and distributed across nodes for parallel execution. Once each node finishes, results are combined and returned.Because each node is self-contained, there's no central resource contention, the architecture scales horizontally. Add more nodes, get more throughput. This is exactly why cloud-native MPP platforms can handle petabyte-scale queries without grinding to a halt.
In managed cloud data platforms, this scaling happens automatically or on demand. You don't provision hardware, you adjust compute based on the workload. That elasticity is precisely what makes pushdown ELT, keeping transformation logic inside the warehouse, such a powerful approach.
To really understand Massively Parallel Processing, it helps to contrast it with Symmetric Multiprocessing (SMP), which is the more traditional model you’ll find in single-server systems typically found on-prem or with legacy data processing systems.
In an SMP (Symmetric Multiprocessing) setup, multiple processors share the same memory and storage within a single server. Scaling in SMP systems means upgrading to more powerful hardware on that one machine. This is known as vertical scaling. While this approach can provide more processing power by adding CPUs or memory, it quickly becomes expensive and runs into practical limitations: there are physical and financial limits to how much you can upgrade a single server. As workloads grow, the shared resources like memory and storage buses can become bottlenecks, ultimately capping performance and efficiency.
MPP handles things differently. It spreads both the data and the computation across separate nodes, each with its own resources. That separation removes the memory and CPU contention you get with SMP and makes MPP far better suited for heavy-duty analytics and large-scale data processing.
MPP didn't start in the cloud. Teradata was formed in 1979 as a collaboration between researchers at Caltech and Citibank's advanced technology group, with a mission to build a database computer that could handle the data volumes enterprises were generating. Teradata released its DBC/1012 database machine in 1984, with Citibank as an early customer, pioneering parallel processing for enterprise data warehousing.
Netezza came later, founded in 1999, it changed its name to Netezza Corporation in 2000 and introduced the concept of the data warehouse appliance: tightly integrated hardware and software purpose-built for analytical workloads. Both platforms ran on expensive on-premise hardware, but they established the foundational ideas, distributed compute, shared-nothing architecture, parallel query execution, that cloud MPP would later inherit and scale.
The shift came when cloud-native platforms like Snowflake, Amazon Redshift, Google BigQuery, and Azure Synapse Analytics decoupled compute from storage and made elastic scaling viable. MPP didn't change; the delivery model did. The result is petabyte-scale analytical performance, without managing a single rack.
Not all distributed systems are built equal. MPP sits within the broader category of distributed data processing, but it was designed with a specific job in mind: high-performance, large-scale analytics. That distinction matters, and it's worth understanding before drawing comparisons.
Distributed data processing is a broad category. It describes any system that spreads compute tasks across multiple nodes, but breadth doesn't mean uniformity.
General-purpose distributed frameworks (think traditional Hadoop or Apache Spark deployments) were built for flexibility: batch processing, unstructured data, machine learning pipelines. They can handle huge volumes, but SQL-based analytics has historically required significant tuning, custom orchestration, and careful attention to data locality. Performance is workload-dependent and rarely automatic.
MPP takes a narrower, sharper approach. It's purpose-built for relational analytics, SQL queries distributed across a cluster, with orchestration, query planning, and result aggregation handled natively. The result is a system optimized specifically for throughput, concurrency, and the kinds of complex joins and aggregations that define enterprise analytics. Less configuration, faster results, better fit for data warehousing and ELT.
For enterprise data teams, the real advantage of MPP comes down to performance, scalability, and simplicity:
Data demand isn't slowing down. Every new AI initiative, every product team spinning up its own analytics, every executive wanting a live dashboard, they all put more pressure on the same infrastructure. Traditional systems weren't built for this. They hit limits fast: slow queries, resource contention, and engineering teams spending more time managing bottlenecks than building things.
MPP was designed for exactly this environment. It distributes the load, executes in parallel, and scales without the manual intervention that legacy architectures demand. For enterprise teams, that means faster insights, fewer escalations, and data infrastructure that keeps pace with the business, rather than becoming the reason things stall.
As data architecture has evolved, ELT has become the dominant approach for enterprise-scale workloads. Unlike traditional ETL, which extracts data, transforms it externally, then loads it into the warehouse, ELT loads raw data first and runs transformations directly inside the warehouse. No intermediate systems. No unnecessary data movement.
This is where MPP becomes a genuine differentiator. By keeping transformation logic inside the MPP engine, you push the computation down to where the data already lives. This is known as a pushdown architecture: instead of pulling data out for processing, you execute transformation logic natively within the warehouse, using its distributed compute to run operations in parallel across the cluster.
The practical result is lower latency, better scalability, and simpler data pipelines. Everything runs in one system. MPP handles concurrency natively, so multiple ELT jobs can execute simultaneously without degrading performance.
The caveat: your data integration tooling needs to be built for this pattern. Legacy tools weren't designed to delegate computation to the warehouse engine. Maia is, and that distinction has a direct impact on pipeline performance at scale.
Maia is purpose-built for cloud MPP platforms, Snowflake, Databricks, and Amazon Redshift. That's not incidental. It shapes how pipelines are designed, how transformations execute, and how fast data moves from raw to ready.
Maia pushes transformation logic directly into the MPP engine. Data stays in the warehouse. The compute power of the MPP cluster, distributed, parallel, scalable, does the work. This eliminates the overhead of moving data between systems for processing, and it means query performance scales with your infrastructure, not against it.
Maia offers a visual pipeline designer for teams that want speed and accessibility, alongside full SQL support for engineers who need precise control. Both approaches run natively on the MPP engine, no performance compromise, regardless of how a pipeline is built.
When Maia runs on an MPP platform, there's no extraction step for transformation. Processing happens where the data lives. That reduces latency, lowers compute cost, and keeps pipelines performing consistently as data volumes grow.
MPP has become the default architecture for cloud-scale analytics, and for good reason. Distributed compute, horizontal scalability, parallel query execution: these aren't advanced features anymore, they're table stakes.
The real question is whether your data tooling is built to take full advantage of it. Legacy pipelines that move data out of the warehouse for processing, or tools that weren't designed with pushdown execution in mind, leave performance on the table.
Maia is designed to close that gap, running transformation logic natively on the MPP engine, scaling with your data, and removing the manual overhead that slows data teams down.
Book a demo to see how Maia runs on your MPP platform.

